Featured product · Full-stack
Fantasy Football Foundry
This is one of the largest products I have built on my own. It is a full-stack fantasy football app with rankings, analytics, draft tools, trade and team workflows, Sleeper integration, content publishing, and a real data pipeline behind it. I built the application, the data model, the stats workflows, the deployment path, and the product experience. All of these are built from scratch using modern tools and best practices in AWS.
Stats and models
More than a rankings table
Foundry runs a dozen stat and value models, plus the scoring and publishing pipelines that keep them live. Some are traditional player-value models. Some are weekly decision boards. Some turn expert input or draft data into durable app data. The hard part is keeping them consistent, explainable, and usable in a live product.
Base player data
- PlayerAnalytics — the main player metrics store that feeds dashboards, comparisons, rankings inputs, trade analysis, and team analysis.
Value models
- VORP — replacement-aware fantasy value for full PPR, half PPR, and standard scoring.
- Market inefficiency — where model value and market value appear to diverge.
Opportunity and production
- XFP — expected fantasy points based on opportunity.
- Opportunity trends — recent usage movement and role changes.
- Breakout candidates — players whose usage, profile, or situation suggest upside.
Player profile models
- QB Lab — quarterback style and process profile.
- Skill Lab — rushing and receiving profile for backs, receivers, and tight ends.
- Combine model — prospect athletic profile and draft context.
Risk and context
- Consistency — volatility, floor, ceiling, and week-to-week reliability.
- Strength of schedule — team and position schedule context.
- Injury risk board — workload, availability, and injury-context scoring.
- Game script outlook — expected game environment and team-level script.
Ranking and publishing models
- Composite rankings — redraft, dynasty, rookie, expert, and model-weighted boards.
- Expert ranking snapshots — publishable expert inputs stored as app data, not live spreadsheet dependencies.
- Draft prospect lane — rookie and NFL draft data feeding rankings and simulators.
- Team analysis and recommendations — roster-state outputs used in team workflows.
- Homepage preview builders — generated rankings and content payloads for public pages.
Why it is hard
Fantasy data is messy. Seasons change. Scoring formats change. Player roles change during the week. Public data, user-authorized Sleeper data, expert rankings, and prospect data all have different shapes and update rhythms. I built the system so the app can rebuild models locally, publish snapshots, serve stable data in production, and tell the user when a number is solid versus directional. That is a lot more work than making a chart look good once.
What ships in the product
The site is really a bundle of related apps. A user can read rankings, compare players, run draft scenarios, look at trade/team context, connect Sleeper, and read research. All of that sits on the same codebase and data platform.
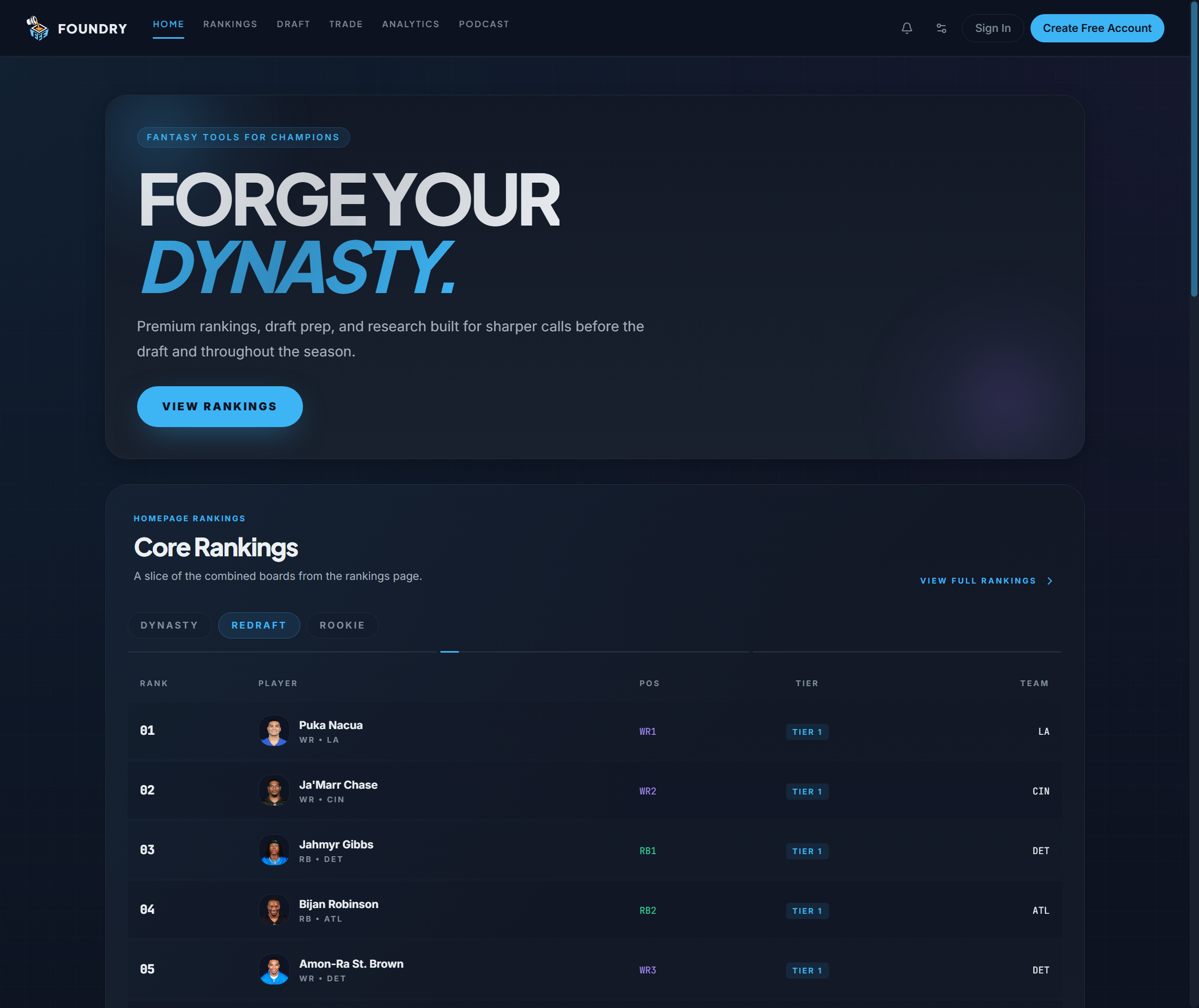
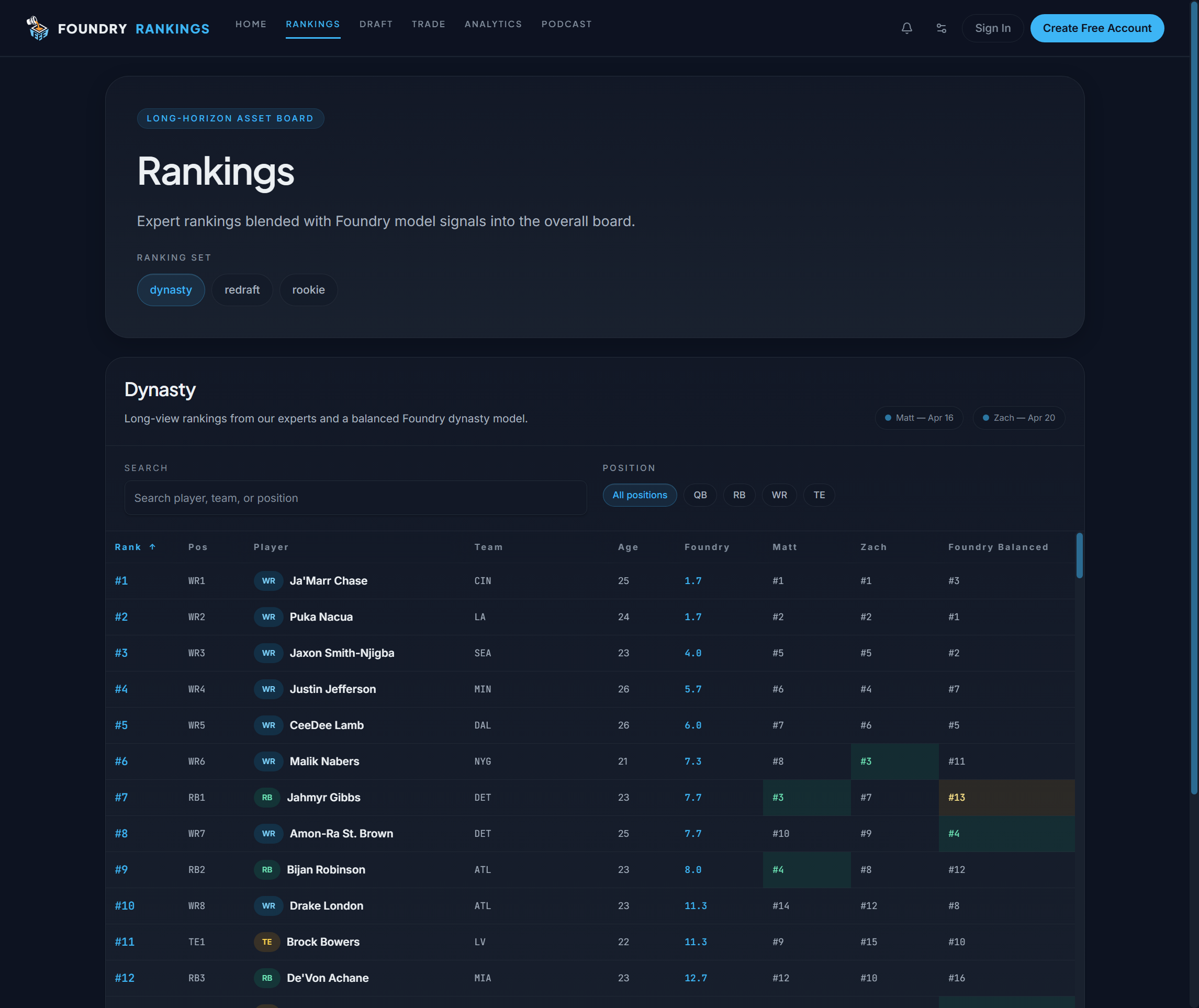
Rankings & value
Redraft, dynasty, and rookie boards. The rankings combine expert inputs, model outputs, and separate weighting logic for different formats.
Analytics hub
Dashboards, player tabs, comparisons, and deeper stat views backed by stored data and prebuilt snapshots. The goal is to make advanced metrics usable during actual fantasy decisions, not bury people in raw tables.
Draft intelligence
A fantasy mock draft simulator, NFL draft tooling, prospect data, rookie context, and draft-prep workflows. This is effectively a second application inside the product.
Trade, team & Sleeper
Trade evaluation, team analysis, and Sleeper-aware context so a user can move from generic player research into roster-specific decisions.
Research & player experience
Player detail pages, methodology notes, and labels for confidence or preview data. I wanted the product to be clear about what is solid, what is directional, and what is still being tested.
Content & editorial systems
Blog, podcast, homepage preview, expert rankings publish flow, and separate visual/storytelling tools for research pieces. The content system gets the same engineering treatment as the analytics.
Full-stack architecture
I kept the stack practical: typed APIs, relational data where it matters, snapshots for heavier model output, and a frontend that can support several workflows without turning into six separate apps.
- Frontend
- Next.js App Router, TypeScript, Tailwind, Radix, shadcn/ui, and Recharts.
- API & data access
- tRPC, TanStack Query, Prisma ORM
- Data
- Postgres for app/runtime state, local development data, and prebuilt snapshots for heavier analytics routes.
- Auth
- Amazon Cognito for sign-up, user groups, and phased access.
- Production
- AWS with CloudFront, ECS Fargate, RDS, S3 snapshots, CI/CD, and infrastructure docs in the repo.
Data platform & modeling
The data approach is simple on purpose: pull durable football data, normalize it, run models, publish snapshots, and serve those outputs through the app. The app should not depend on a live spreadsheet or a random API call in the middle of a user workflow.
The repo has separate docs for the model catalog, data architecture, pipeline, production data handoff, expert rankings workflow, deployment, and security baseline. That matters because the product has to be rebuilt, refreshed, debugged, and operated.
Day-to-day work runs through a documented local pipeline (npm run pipeline:local, pipeline:validate) plus quality checks for mock analytics, live-fetch mistakes, and snapshot freshness.
My ownership
- Designed the product, information architecture, and core user flows.
- Built the Next.js application, shared components, data-loading patterns, and server routes.
- Designed the data pipeline around nflverse-class sources, local rebuilds, Postgres, and snapshots.
- Built rankings logic, model blend rules, expert publish flows, and homepage preview generation.
- Added Sleeper-aware workflows for roster and league context.
- Documented the pipeline, deployment path, security posture, and production runbooks so the project can be operated, not just demoed.
The private repo has the deeper detail: model inventory, data architecture, publish workflow, deployment runbooks, and security notes.
Product screenshots
Captured from the live site for this portfolio (not a separate design mock).